

La macchina per DITA

tratto da technische kommunikation | Volume 30 | 5 / 2008 | Page 30
DITA Open Toolkit alla prova dei fatti
di Ferdinand Soethe
DITA Open Toolkit, una delle implementazioni di riferimento dell'architettura DITA (Darwin Information Typing Architecture), viene considerata da molti addetti ai lavori come un'applicazione dotata di un approccio pragmatico. Alcuni provider commerciali fanno persino a meno delle proprie implementazioni DITA e si servono della licenza del Toolkit, e della sua libertà d'uso, per offrire proprie applicazioni DITA basate su questa piattaforma.
Per scoprire come si comporta l'Open Toolkit alla prova dei fatti, è stato programmato un test pratico in due parti. Il primo compito consisteva nella realizzazione di una bozza della documentazione tecnica di un programma software stand-alone destinata sia ad essere stampata sia ad essere fruita in formato HTML Help. La versione stampata comprendeva parecchie centinaia di pagine e l'idea per la seconda fase del progetto era di rimettere mano alla documentazione per una variante del programma. Insomma, un caso ideale per l'applicazione dell'architettura DITA e del Single-Source-Publishing.
Un avvio veloce
L'inizio è stato promettente: gli sviluppatori sembravano aver imparato la lezione dopo i problemi incontrati con le versioni precedenti del DITA Open Toolkit e avevano pertanto snellito il processo di installazione singola degli otto componenti, scomodo e soggetto ad errori. Nella variante "tutto compreso" [1] l'installazione richiedeva unicamente la decompressione di un file archivio. Un prerequisito perché DITA possa funzionare è, però, che Java SDK sia già stato installato. È bene sottolineare, a questo proposito, che la più diffusa versione di Java Runtime Edition (JRE) non è sufficiente. Informazioni più dettagliate in merito sono disponibili nel manuale DITA OT [2].
Occorre poi fare un po' di abitudine a quel che accade dopo: startcmd.bat non lancia l'elaborazione DITA e non c'è una finestra del programma. Al suo posto si apre una finestra di terminale ("DOS") in cui, per fortuna, i parametri corretti per l'ambiente sono già stati impostati. In questa finestra, inoltre, l'utente può avviare l'effettiva elaborazione DITA di un progetto immettendo certi comandi.
Impostazione di un progetto
Il manuale consiglia di creare una cartella separata per ogni progetto, soprattutto perché la cartella del Toolkit potrebbe venire completamente sostituita in occasione di successivi aggiornamenti di DITA. L'esperienza insegna che è meglio che l'utente si astenga dall'aggiungere alcunché all'albero delle cartelle del Toolkit in quanto esso è già sufficientemente complesso.
Perciò, per il nuovo progetto, ho creato una nuova cartella dal nome "manuale" dentro alla quale ho creato quattro sottocartelle:
- Sorgente: contiene tutti i file sorgente del progetto vero e proprio. I file di grafica e le immagini sono contenute in un'altra sottocartella che ho chiamato Immagini;
- Build: la cartella target per tutti i prodotti DITA. Per ogni formato di output ("target") DITA crea una sottocartella specifica che prende il nome del formato (pdf, xhtml, htmlhelp);
- Log: contiene tutti i rapporti di una sessione DITA;
- Temp: è una cartella che viene creata automaticamente durante l'elaborazione e ne contiene i risultati provvisori. Possiamo tranquillamente ignorarla.
È una distribuzione consigliata soprattutto quando si intende utilizzare un sistema di controllo versione quale CVS o Subversion [3]. Le versioni vengono assegnate solo alla cartella sorgente. La configurazione del progetto è ben ideata in quanto nel ramo dell'albero monitorato non sono presenti file generati automaticamente che, altrimenti, sarebbe necessario escludere manualmente dal controllo di versione.
Preparazione del contenuto
Nella fase di creazione del contenuto è necessario disporre di uno strumento affidabile. Come in tutti progetti XML, vale la pena avere a disposizione un Editor XML professionale che supporta le DTD o gli schemi, poiché la sintassi DITA non è sempre autoesplicativa o intuitiva.
Ciononostante, la creazione di nuove pagine non rappresenta un problema poiché molti nomi di elementi e concetti sono basati su dialetti XML diffusi quali DocBook e XHMTL. Perciò "ul" anche in DITA è un elenco non ordinato e la nidificazione del capitolo è mappata con "section".
Un piccolo svantaggio è rappresentato da nomi di elementi brevi ma spesso ambigui, come "p" per il paragrafo. Ciò rende il riferimento agli elementi assolutamente necessario in quanto, all'inizio, sì è costretti a controllare continuamente il significato presunto con la documentazione.
Ancora meglio se l'editor inserisce la spiegazione dal documento DITA già quando si scrive il nome dell'elemento, come illustrato nella figura 1.
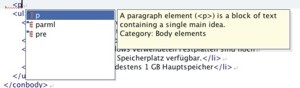
Fig. 1: DITA-Doc in veste di help all'interno di XML Editor
Infotype versus flessibilità
Sfortunatamente, in alcuni casi la sintassi DITA è una camicia di forza. Nei Task-Topics, l'elenco delle condizioni (prereq) deve necessariamente venire prima dell'elemento context, vale a dire persino prima delle informazioni di base sul compito. Questa sequenza, tuttavia, non ha molto senso quando si tratta di documentazione.
In questo caso, sarebbe desiderabile avere più spazio di manovra. A questo punto, l'utente comincerà a prendere in considerazione una specializzazione, cioè l'estensione e la modifica della sintassi DITA. Ma è più facile a dirsi che a farsi e, a ogni buon conto, non era questo lo scopo del progetto. A causa di questa rigidità, più spesso di quanto si pensi l'utente si sposta sull'elemento radice generale "dita" e vi colloca Concept e Task-Topic per poter disporre della necessaria flessibilità. Questo modo di procedere è chiaramente in contraddizione con la tipizzazione dell'informazione caratteristica di DITA, cioè un chiaro typecasting di ogni topic.
Le DITAMAP: un sommario flessibile
Ancora una volta, DITA ovvia alla mancanza di flessibilità della sintassi tramite le DITAMAP. Ciò che a prima vista potrebbe sembrare la versione XML di un documento master, a uno sguardo più ravvicinato si rivela un vero e proprio capolavoro dell'architettura dell'informazione.
Così, l'aggregazione di topic in un unico Topic Element successivo a un "sottocapitolo" può anche indicare diverse correlazioni tra i topic: è possibile mappare tutto, a partire da una sequenza rigidamente organizzata, quale quella delle diverse fasi di un processo, sino a un insieme di topic allo stesso livello.
La cosa più stimolante è che, quando si producono output con strumenti modulari, come l'HTML o HTML Help, il Sommario viene visualizzato in modo completamente diverso. Uno sguardo veloce al repertorio dei trucchi può aiutare a mettere a frutto il potenziale insito nel proprio progetto. La conferenza di Scott Stark rappresenta un'ottima introduzione al riguardo [4].
Riutilizzo modulare: ben più di una promessa
La possibilità di riutilizzare ogni elemento di qualsiasi documento DITA in una diversa posizione grazie all'attributo conref è sicuramente di grande utilità pratica. Se associata a un editor che non ha problemi a supportare questa tecnica, la procedura di riutilizzo acquisisce una dimensione totalmente nuova.
Per il manuale di software del nostro test, ad esempio, metto innanzi tutto delle pagine di overview con elenchi di schermate, azioni ed elementi di menu rimandando d'ora in poi a questi elementi soltanto con dei conrefs ogni volta che si usa la schermata o il comando di menù (figura 2).

Fig 2: Esempio schematico di riutilizzo con Conref
In questo modo, il nome di ogni menu e schermata del progetto viene definito in un'unica posizione, facilmente rintracciabile nell'overview, ogni modifica del testo nel programma può essere ricostruita cambiando questa posizione in tutta la documentazione.
La palla passa all'editor
Naturalmente, ciò richiede un certo livello qualitativo dell'editor. Persino la costruzione a mano di riferimenti conref può costituire un'impresa assai difficoltosa. Quando si legge un testo con struttura altamente modulare in XML, fare correzioni non è certo comodo. Un editor con speciali finestre di dialogo può semplificare la costruzione dei conref (figura 3).
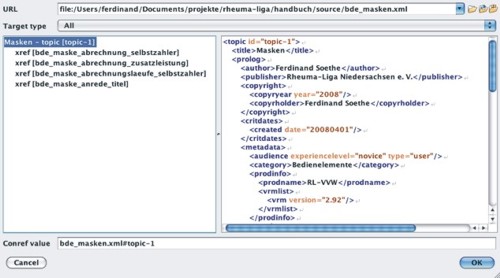
Fig. 3: Finestra di dialogo dell'help per la costruzione di un riferimento conref
Inoltre, sarebbe sicuramente utile che l'editor consentisse la visualizzazione dei contenuti inseriti con conref durante le operazioni di editing (figura 4):

Fig 4: Visualizzazione di conref nell'editor XML
La figura mostra delle incontrovertibili difficoltà iniziali: gli elementi inline ("uicontrol") integrati con conref vengono visualizzati dall'editor (Oxygen) come blocchi per cui la sequenza dei menu può essere individuata solo grazie a molta immaginazione. Si spera che questi problemi verranno risolti al più presto, in modo che non ci siano più ostacoli a un funzionamento efficiente.
Ant e dintorni
Dopo aver completato alcune pagine, è giunto il momento di dare avvio alla prima sessione di traduzione. Prima di tutto, desidero vedere il progetto sotto forma di pagine HTML e, per fare ciò, devo creare un file di controllo che, secondo le indicazioni di DITA "è la cosa giusta da fare." Si può pensare di utilizzare Ant, che recentemente è diventato molto popolare. Ant è un linguaggio di programmazione di Apache Software Foundation, indipendente dalle piattaforme che agisce, per così dire, come un collante tra i componenti di DITA [5].
Naturalmente non ha molto senso studiare e impratichirsi nell'uso di Ant solo per lavorare con DITA. È più sensato personalizzare i file di controllo esistenti in base alle proprie esigenze. Tuttavia, i file di controllo del Toolkit (build_*.xml) non servono allo scopo, perché la loro struttura è troppo complicata. Meglio guardare nella cartella del Toolkit che contiene esempi semplificati. Ma, poiché anche questi sono troppo complessi per un neofita di Ant, ho messo sul Web un file commentato e le relative istruzioni in tedesco [6].
Vicini alla meta
Dopo che il file di controllo è stato messo a punto, le successive operazioni di elaborazione sono solo un gioco da ragazzi. Tutti i supporti e i formati necessari vengono generati semplicemente premendo un pulsante e si riveleranno di grande utilità (figura 5). È stato necessario solo rielaborare l'ampio spazio prima degli elenchi puntati, problema già risolto e documentato nella mailing list DITA.

Fig 5: Produzione di una pagina HTML
Per sistemi di help come Windows HTML Help, DITA crea file di progetto completi, che devono essere aperti e tradotti con il relativo Help Compiler. Come si può vedere nell'esempio relativo a Windows Help nella figura 6, DITA crea una visualizzazione coerente in tutti i tipi di supporti e formati.
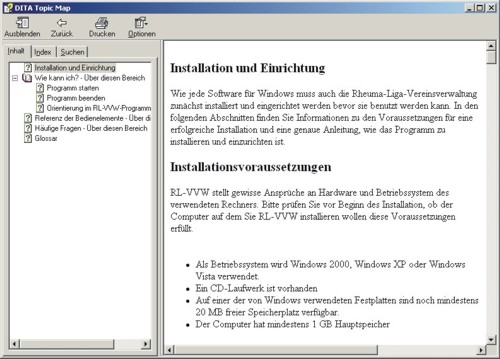
Fig 6: Produzione di file di Windows HTML Help
I compilatori freeware per Windows Help e per JavaHelp di Sun devono essere installati separatamente alla luce delle restrizione sulle licenze [7, 8].
Filtri per i capitoli "conditional"
Ora ci occuperemo di due varianti del programma per la gestione degli elementi "conditional". Dal punto di vista di DITA, si tratta di un passaggio molto semplice perché ogni elemento DITA contiene fondamentalmente gli attribuiti per gestire prodotto, piattaforma, destinatario, versione e una caratteristica di libera scelta. Pertanto, singole sezioni o persino interi Topic possono essere contrassegnati e, se necessario, il progetto può essere successivamente filtrato in base a caratteristiche singole o loro combinazioni, come illustrato nella figura 7.
![]()
Fig 7: Sezione "conditional" nell'editor
Purtroppo la visualizzazione delle sezioni conditional è ancora carente in molti editor XML. Il risultato dell'applicazione della funzionalità conditional può essere verificato solo dopo l'elaborazione DITA, ma è anche vero che si tratta di problemi risolubili se l'editor in uso consente una sufficiente flessibilità di configurazione. È possibile trovare una soluzione per Oxygen su Internet [6].
Se le caratteristiche del testo rimangono costanti, il lavoro con i filtri può decollare. L'introduzione è scarsamente documentata ma in Internet si può trovare un template con le spiegazioni [6]. Una volta partito, il sistema funziona bene e può essere configurato con flessibilità.
Segnalazione con flag
In alternativa ai filtri, l'utente può evidenziare visivamente gli elementi tramite un sistema di flag. Il meccanismo è molto utile per evidenziare visivamente le modifiche di contenuto negli aggiornamenti del nostro progetto campione. Poiché i flag coesistono con tutte le funzionalità di filtro, è possibile utilizzarli anche nelle situazioni elencate di seguito:
- sezioni che devono essere riviste (utilizzo delle caratteristiche scelte dall'utente)
- informazioni che si riferiscono al gruppo di destinazione, ad esempio quando ci sono sezioni che si rivolgono solo agli amministratori.
Uno dei principali vantaggi dei filtri e dei flag è che l'utente può inizialmente assegnare delle caratteristiche agli elementi e decidere solo in una fase successiva come gestirli a seconda della necessità.
Conclusioni
Dalle risultanze del mio test emerge che il progetto DITA si è rivelato all'altezza di tutte le aspettative e possiede funzioni interessanti che ne fanno un sistema utile per la gestione del Single Source Publishing. Tuttavia, per sfruttare appieno le possibilità del sistema, è necessario possedere una conoscenza approfondita di DITA e dei concetti su cui si fonda. OItre allo studio, irrinunciabile, della documentazione DITA l'utente potrà consultare in Internet un'ampia gamma di saggi e presentazioni redatti da esperti di DITA. Il requisito minimo è che ogni autore di topic sia in grado di leggere i documenti DITA anche nel codice sorgente.
Coloro che scrivono documentazione con il metodo Top-Down sono generosamente ricompensati da DITA. Ulteriori lavori preparatori e uno schema per nominare i file e gli ID sono particolarmente utili se si pensa di riutilizzarli. Lo stesso vale per l'acquisto di editor XML in grado di gestire DITA.
Ciononostante, per ottenere il meglio da DITA non ci si deve tirare indietro e personalizzarne accuratamente l'installazione.
Collegamenti
[1] DITA-OT1,4.2,1_full_easy_install_bin:
http://sourceforge.net/project/showfiles.php?group_id=132728
[2] DITA: guida dell'utente:
http://dita-ot.sourceforge.net/SourceForgeFiles/doc/user_guide2.html
[3] Home page di Subversion:
http://subversion.org/
[4] Scott Stark (IBM), DITA Linking and Relationship Tables:
www.ditausers.org/tutorials/presentations/Stark_Links/
[5] Ant:
http://ant.apache.org/
[6] Altri materiali DITA in rete:
http://soethe.net/dita
[7] Per scaricare Windows HTML Help:
http://msdn.microsoft.com/en-us/library/ms669985.aspx)
[8] Download di Javahelp
http://java.sun.com/javase/technologies/desktop/javahelp/download_binary.html
Alcuni indirizzi utili
DITA-OT: guida dell'utente:
http://dita-ot.sourceforge.net/doc/ot-userguide/ditaotug141-03122007-pdf
-Homepage DITA su Sourceforge:
http://dita-ot.sourceforge.net
Homepage della Community DITA:
http://dita.xml.org/
Sito Web degli utenti DITA:
http://www.ditausers.org/
Materiali di riferimento Online per DITA:
http://www.ditainfocenter.com
Ferdinand Soethe è un architetto del software professionista e fornisce consulenze per la selezione, la personalizzazione e l'introduzione di sistemi software complessi. Dal 1996 l'utilizzo di sistemi SSP per la documentazione tecnica costituisce un aspetto importante del suo lavoro.
Recapito di posta elettronica: mail@soethe.net


